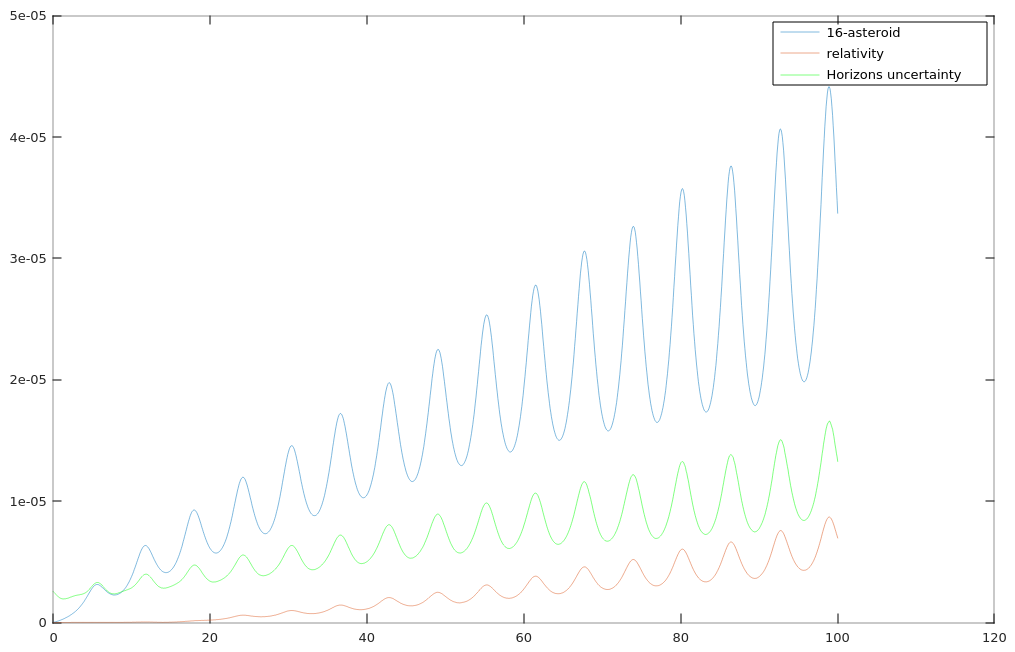
Some updates on my high fidelity heliocentric propagation study. Good news, for my sample asteroid I’m able to match the Horizons reference ephemeris to within the uncertainty Horizons has on it. Over 100 years that’s about 200 km position error and less than 1e-5 km/s velocity error. I have two plots attached to show that. To get that I have to include the top 16 asteroids (beyond that it doesn’t make much difference) and general relativity. I also had to implement a sun-centered version of the ICRF frame.
At a minimum I would like to get the sun-centered ICRF frame in the main source code.
I have a JPL Ecliptic frame coded as well but I need to experiment with that more to confirm it’s working as well as the sun-centered ICRF. I couldn’t get barycentric working well at all. That’s for another discussion though.
There is also the question of the reference asteroid ephemeris. For now I have it coded up to read it out of a SQLite database. Do we think our SPICE bsp file readers would be able to read generic SPICE files not just the DE files? If so it may be better to ingest it that way rather than bringing in SQLite dependencies and their exceptions. Assuming the SPICE idea works having it in the main source code is a lot easier of a solution.
There are some light documentation updates needed too around Earth-centric terminology used for certain things (like the Relativity force model) and some clarifying of documentation on changing out DE files.
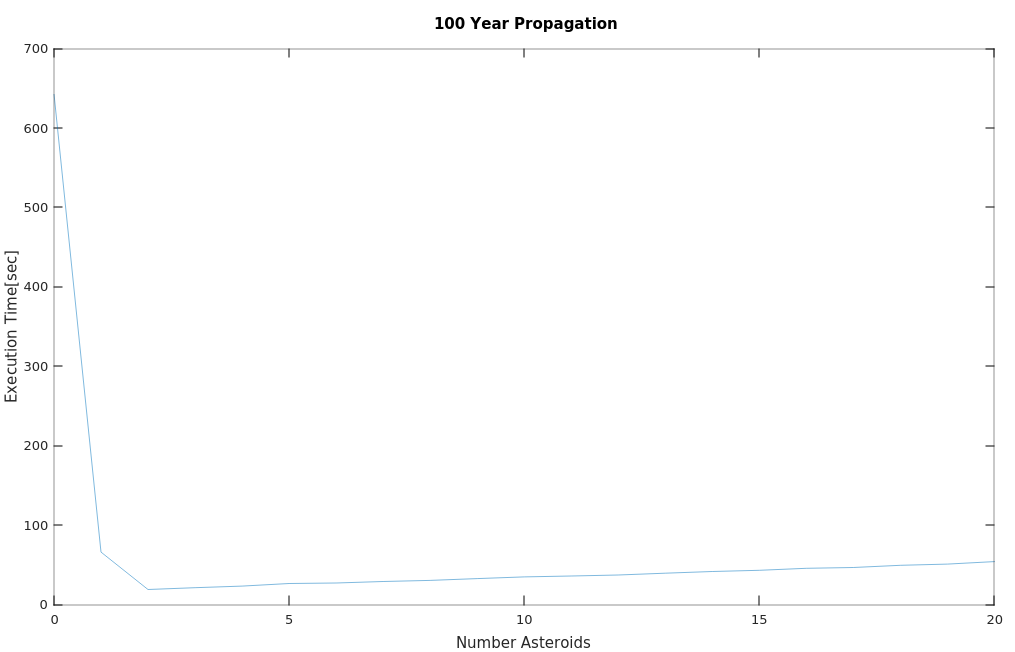
An interesting thing which may be of note is the time of propagation. When I was running my unit tests the 100 year propagation were taking excessively long, on the order of ten minutes. I was expecting I’d have to run JProfiler to see where we could get some optimization. However when I ran a test case where I was marching through the number of asteroid perturber count I found a pleasant surprise. It seems that it was the initial pass building up the polynomials where we really take the hit. For a “warmed up” case where we have the fully loaded all the planetary ephemeris and started loading asteroid ephemeris the run time drops down to 20 seconds, then starts increasing from there. I ran a subsequent test where I “warmed up” the ephemeris caches and confirmed this. I don’t know if there is a more efficient way to do this than to just march through time but I thought it was worth highlighting. it’s a problem for one off computations but less so for persistent servers.
We’ve had some discussions about that. Adding support for generic SPICE files could be a good new functionality for Orekit. I don’t know where those discussions stand. But I think that nothing has been done to add support for generic SPICE files. I hope someone will confirm what I’m saying.
That’s a strange behavior. Is there an optimization problem with your data loader? But I’d be curious to use an optimization engine to see why exactly it taker about 10 minutes at the beginning.
Thank you Hank for your work and your updates. That’s really interesting!
I confirm that (to my knowledge) nothing has been done on SPICE kernels reading with Orekit.
I do also think this would be a very good addition.
The feature was asked by a user during the first Orekit day back in November 2017. But no one asked for this again since then and no one had time or need to do it for a project.
Your project may be a good opportunity to develop this feature Hank.
This is with the JPL Planetary loaders built into Orekit for all the major solar system bodies. It’s not that strange really since I think it only loads the segments that it needs for a given computation. Once it’s loaded it’s permanently cached. However before that it goes through, figures out what to load, loads it, builds up the equations etc. What I don’t know is if it is possible to bulk load the caches with the entire DE file. That’s what I’m doing for the asteroids when I first encounter one.
On the SPICE kernels in Orekit we would have two options. The first option would be to use the standard JPL libraries. The second option would be to write our own libraries with extensive unit tests for just the parsers aspect of reading (maybe also writing) SPICE files. The big advantage of using the JPL libraries are that they are heavily validated and hypothetically maintained by JPL along with the other language implementations. The bad news is that they are not Java Native. They use JNI to call down into the C-libraries. The other bad news is that as far as I can tell they don’t have them pushed up to a Maven repo anywhere. That means we’d have to handle their library somehow and train our build scripts to be platform aware (both CPU and OS). It could be a great service to write JVM native versions of this library, even if just for a subset of SPICE capabilities, but it would not be a small development operation.
Yes I suspected this would require a large development.
Do you know if they have publicly available test cases somewhere ? This would at least reduce the amount of time required.
They do ship with a test suite. I’m not sure how directly usable it would be since it is very specifically hardwired to the JNI calls in their native libraries but it would be able to be used to create a reference unit test for another library.
I have recently become interested in loading SPK binary kernels in Orekit and found this thread! Would there still be interest in this feature? If so I’d be happy to contribute towards implementing readers and evaluators for the different types of SPK kernels. I think it could be interesting, since there is a lot of information available distributed as SPK kernels. I have available a test suite for loading and evaluating all kernel types, with results verified against those produced by CSPICE, which we could easily port to Java.
I’m so sorry it took me so long to get this done! But I finally have a first draft of support for SPK reading and evaluation. I have opened opened an issue here, and created an MR here, but just as a preview/first draft! I’m still in the process of adding proper documentation, checks, exceptions, etc, but since I got it to the point where the test suites complete succesfully, thought I’d share already in case the team wants to have a look
Together with the new features, I have added test suites validating reading and evaluation of SPK files against a set of test files for each SPK type. I have validated these results against those obtained by my asteRisk suite, which in turn I validated to match exactly the results obtained with CSPICE when reading/evaluating the exact same test files.
I have much more in the works, including support for text-based SPK kernels, writing binary and text SPK kernels, support for other kernels and more, but I thought it would be a good idea to consolidate on this before adding more!
It looks like a huge work, no wonder it took you a while.
Thanks so much for this ! That’s definitely a super nice feature for Orekit.
That’s awesome. Maybe you should try to split your work into several issues and several merge requests? It takes a while to review code and we’re all very busy. Your current merge request has almost 10000 of brand new line of codes, wow!
I mean, that great! But it may takes a while to review
@MaximeJ thanks a lot for the enthusiasm about the new feature!
And my apologies for such a large merge request. Definitely moving forward I will be adding proposals for new features in separate, smaller issues/merge requests.
Completely understand that it takes a while to review so much code! Would it help to split also the current merge request into smaller parts?
The very broad architecture is:
There is a very generic file type known as DAF (double precision array) files
So we need classes to hold DAF files and their different parts, as well as parser
SPK files are one of the file types (but not the only one) based on DAF files. They are basically DAF files whose components should be interpreted in a particular way to arrive to meaningful information. The interesting part is that there is not a single SPK type, but nearly 20, and each of them has a specific arrangement of elements and a specific way to use these to obtain state vectors. These vary a lot, for example, for type 2 (this is the SPK type used by binary JPL DE) Chebyshev coefficients for position that should be evaluated together with their derivatives e.g. through Clenshaw algorithm, but for type 10, TLEs that should be evaluated with SGP4/SDP4.
This means we need classes to hold each SPK type, each including an appropriate evaluate method taking a target date and returning a state vector as output, and then a parser that acts on an already parsed DAF file, considers the SPK type to interpret it correctly and returns an SPK of the correct type.
So if it helps, I could try to split the merge request e.g., a first one for DAF files only, then additional ones for different parts of the package dealing with SPK themselves? At the same time, I tried to put these functionalities into different subpackages in the current merge request. Let me know what would be the most convenient for the team!
No need for an apology
I’m sure this will be a great addition to Orekit!
In Gitlab you can have a master issue (say the one you opened: #1681) and add either some child items or link items like other issues related to it. That way you can split a very large contribution into smaller items and keep track of the global completion in the master issue. Given the different aspects of the contribution you want to make, I think this would be a good idea to use these features of Gitlab.
I don’t think so. No need to give you extra work. I was just afraid that you would put everything you planned in a single merge request
Quick question (I didn’t have time to check your code yet): did you manage to reuse the class JPLEphemeridesLoader for this one or did you code a brand new class?
I’ve seen on your fork that you don’t have a SonarQube instance (our quality tool) initialized yet.
Could you please follow the part “Configuring SonarQube” at the end of the contribution guide? It will be necessary to validate your merge request.
@MaximeJ thanks a lot! Will definitely use these Gitlab features to keep things organized!
I was not able to reuse JPLEphemeridesLoader since it seems to be designed to specifically handle bodies provided by JPL DE ephemerides, while type 2 SPK segments can provide data for any body (and having any central body). Additionally, it seems to have hard coded shifts to locate specific pieces of data and expect specific constants, e.g., EMRATIO. So for now, I implemented a new class for general type 2 SPK segments, but I’m definitely open to implementing it using JPLEphemeridesLoader, although it might require serious modifications to it, which might defeat its point of targeting specifically JPL ephemerides!
Thanks a lot for the instructions to set up the SonarQube instance, I believe I managed to set it up now!
I think for now what you did is fine. I was just asking out of curiosity.
I didn’t see your fork in the analyzed projects of Orekit’s SonarQube.
For some reasons, the “master” branch of Orekit (that you’re supposed to run in the contribution guide) is not passing on the contributors’ runner.
I suggest you run a pipeline on “develop” instead, this should set you up.
Also, seeing your last pipeline, I think you need to activate checkstyle in your IDE
Thanks a lot for this! It was actually my fault that I did not set up properly SonarQube. I reran the pipeline on master and that seems to have added me to the analyzed projects.
Thanks a lot also for the heads up about checkstyle not being properly set up! It was a fun ride to fix the >1500 checkstyle violations
I see that my Orekit branch is listed as “Project’s Main Branch is not analyzed yet.” , even though I ran the pipeline on my develop branch after my fork being listed in the analyzed projects. Is this something I could fix?