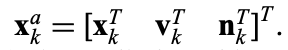I just went through this forum discussion and through the references you shared. From what I read, I understand the following:
There are two versions/options of the UKF for inclusion of process noise. Woodburn [1] writes:
“Literature on the UKF offers two options for the inclusion of process noise: a purely additive approach where a process noise matrix is added to the covariance determined from definitive propagation, or augmentation of the state vector to include process noise states. The latter option, while preferred by some authors since it avoids a re-sampling operation to create new sigma points after the covariance is updated, appears to only be applicable to cases where process noise can be applied in a purely additive sense at the end of a time update without concern for the method of uncertainty evolution over the time update interval. The state vector augmentation approach does not alter the trajectories of the sigma points, it merely utilizes the mechanics of the unscented transform to affect the state error covariance to avoid an additive operation that necessitates re-sampling of the sigma points.”
I believe these two version correspond to the two algorithms presented in Table 7.2 and Tabel 7.3 in the paper by Wan and van der Merwe [2] shared by @markrutten
The algorithm in Table 7.2 requires augmentation of the state: “the state is redefined as the concatenation of the original state and noise variables” (p.230 of [2]):
where x is the original state, v is the process noise and n is the observation noise.
The algorithm in Table 7.3 does not require this state augmentation, but instead requires augmenting or updating the sigma points after the predict step before doing the measurement update. This can be done by either adding sigma points (Eq 7.56 of [2]) or redrawing a complete new set of sigma points (footnote 6 on p.233 of [2]).
I have in the past implemented the UKF wrongly myself. I neither augmented the state, nor augmented/redrawn the sigma points. I realised this when I saw that the innovation covariance did not include the process noise, which is exactly @markrutten’s point if I understand correctly.
I’m still startled by the ambiguity that the presence of these two algorithms can cause.
I agree at 100% that the Table 7.3 algorithm is more interesting. The fact of finding both algorithms in the literature encouraged me to integrate both possibilities in Hipparchus in order to be as generic as possible
Since your two experiences with @markrutten shown that we should only have the Table 7.3 algorithm, then I’m fine with that.
Thanks @bcazabonne and @dgondelach for your time exploring this. It is confusing … as David explained both algorithms (table 7.2 and 7.3) introduce process noise, but in different ways.
I was looking at the pull requests in Hipparchus and found this one, which references this discussion. The request was however opened whicl this discussion was still ongoing.
Is there any consensus or conclusion on this? Should we merge the PR as is or should it be updated?
I think that the changes in my pull request (or something similar) are necessary. “Consensus” might be an exaggeration, but I interpreted the last post by @bcazabonne as reluctant agreement?
The Orekit unit tests are fine. Apologies for not making a pull request with the changes … I was waiting for the change in Hipparchus to happen first.
I’m a bit surprised that I didn’t need to change too many acceptance thresholds. I guess that the process noise used is very small so the differences in implementation don’t influence the results?
There was one issue in “UnscentedKalmanModelTest”, where the state covariance was not positive-definite after the first measurement update. I changed the initial state covariance to be diagonal and the test ran with only a small change to some test tolerances.
The Orekit code changes aren’t huge. The way that I’ve implemented the “getPredictedMeasurements” method in “UnscentedKalmanModel” looks like this
/** {@inheritDoc} */
@Override
public RealVector[] getPredictedMeasurements(RealVector[] predictedSigmaPoints, MeasurementDecorator measurement) {
// Observed measurement from decorator
final ObservedMeasurement<?> observedMeasurement = measurement.getObservedMeasurement();
// Initialize arrays of predicted measurements
final RealVector[] predictedMeasurements = new RealVector[predictedSigmaPoints.length];
// Initialize the relevant states used for measurement estimation
final SpacecraftState[][] statesForMeasurementEstimation = new SpacecraftState[predictedSigmaPoints.length][builders.size()];
// Loop on builders
for (int k = 0; k < builders.size(); k++ ) {
// Convert sigma points to spacecraft states
for (int i = 0; i < predictedSigmaPoints.length; ++i) {
RealVector predictedSigmaPoint = predictedSigmaPoints[i]
.getSubVector(orbitsStartColumns[k], orbitsEndColumns[k] - orbitsStartColumns[k]);
Orbit orbit = orbitTypes[k].mapArrayToOrbit(predictedSigmaPoint.toArray(), null, angleTypes[k],
observedMeasurement.getDate(), builders.get(k).getMu(), builders.get(k).getFrame());
statesForMeasurementEstimation[i][k] = new SpacecraftState(orbit);
}
}
// Loop on sigma points to predict measurements
for (int i = 0; i < predictedSigmaPoints.length; i++) {
final EstimatedMeasurement<?> estimated = observedMeasurement.estimate(currentMeasurementNumber, currentMeasurementNumber,
KalmanEstimatorUtil.filterRelevant(observedMeasurement,
statesForMeasurementEstimation[i]));
predictedMeasurements[i] = new ArrayRealVector(estimated.getEstimatedValue());
}
return predictedMeasurements;
}