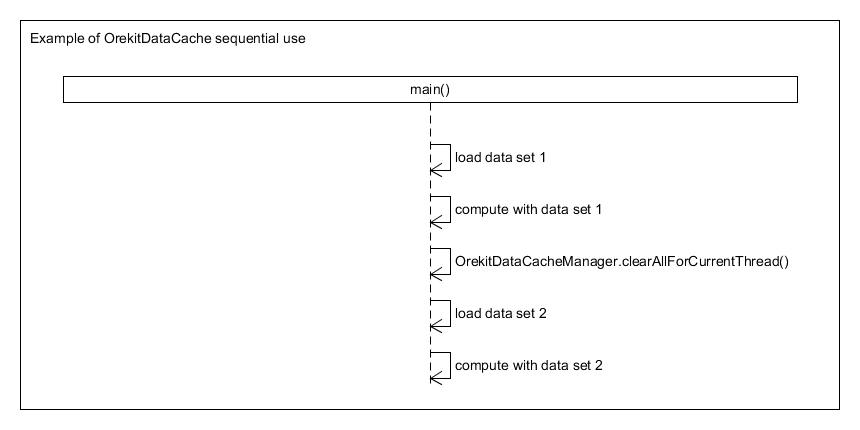
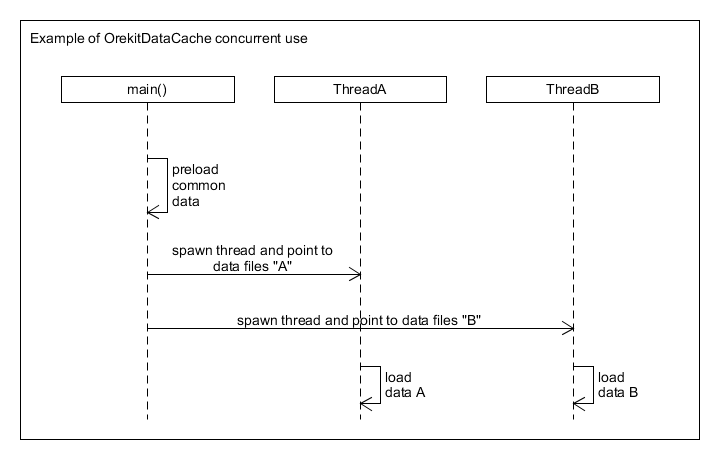
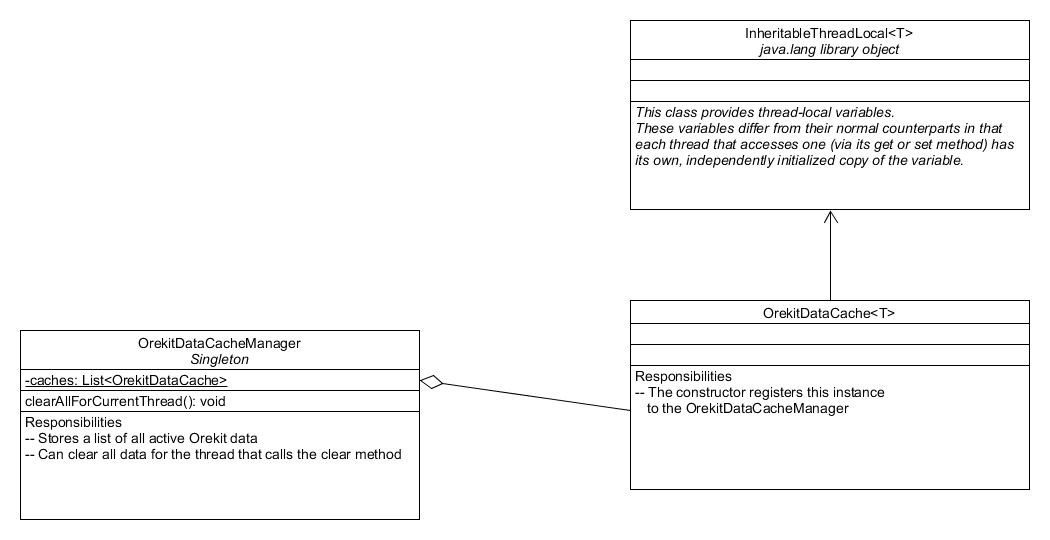
Data Context Proposal
Based on community discussion there is a desire to add the concept of a data context to Orekit that would manage leap seconds, EOP, and everything else that DataProvidersManager is used for.[1-4] My goal here is to consolidate ideas and provide a concrete plan for the community to discuss and provide feedback. I’ll start implementing the changes over the next few weeks.
Motivation
Adding a data context would enable some new use cases:
- Updating leap seconds, EOP, etc. without restarting the JVM. [1]
- Compare multiple EOP data sets within the same JVM.
Updating EOP in a running multi-threaded application is a bit tricky. If the data were updated at an arbitrary point in time this could create inconsistencies leading to incorrect results. Knowing when it is safe to update the data requires application level knowledge which the Orekit library does not possess. So Orekit can provide methods to update the data, but the application has the responsibility for calling them at an appropriate time.
Allowing multiple data contexts enables the second use case and provides flexible options for implementing the data update use case. For example, the application could continue to use the old data set for processing jobs (e.g. threads) that were already started to avoid inconsistencies, but use the new, updated data context for new processing jobs. This would allow a high level of concurrency and a gradual switch over to the updated data set.
The existing architecture has a long track record of providing sufficient utility for a variety of use cases and has some advantages compared to managing multiple data contexts:
- Simple to set up.
- Consistency throughout application.
Consistency is valuable and eliminates a whole class of bugs. It means that an AbsoluteDate corresponds to a single point in TAI and a single point in UTC. If there are multiple instances of UTCScale this is no longer the case as each UTCScale could map an AbsoluteDate to a different point in UTC depending on the leap seconds it has loaded. Consistency is limiting as it becomes impossible to characterized the differences between data sets, one of the new use cases. My conclusion is that out of the box Orekit should be consistent, but allow the user the power to configure multiple data contexts.
Plan
-
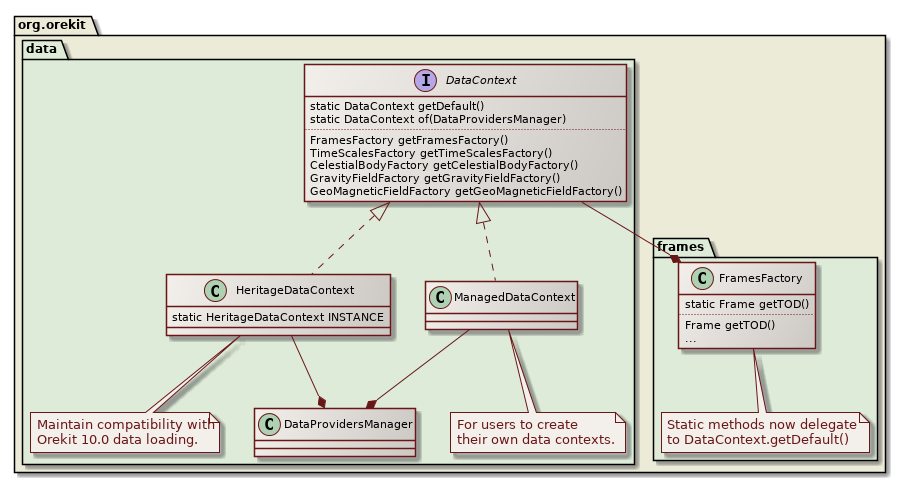
Create a
DataContextthat provides access to frames, time scales, and other auxiliary data.DataContextwould be initialized with a a reference to aDataProvidersManager, which would no longer be a singleton.DataContextwould create instances ofFramesFactory,TimeScalesFactory, etc. which would no longer be singletons. -
Create a default
DataContextsingleton that matches the existing behavior of Orekit. This provides consistency and simple setup to simple applications. -
Add additional contructors/methods to every piece of existing Orekit code that calls methods in
FramesFactory,TimeScalesFactory, etc. Existing methods would use the defaultDataContextand the added methods would accept aDataContextor the specific object needed, e.g.UTCScale.
That would comprise the initial capability that would enable the new use cases while maintaining the existing behaviors for users that do not create their own DataContext. This plan as a UML diagram is shown in below. This plan is based on the one described in [4].
Improvements
While the proposal above would satisfy the stated use cases there are some more use cases that could be added as future improvements.
Frame transformations between contexts
In the base proposal the GCRF frame would be the same in all data contexts because it is the root frame in Orekit. This isn’t necessarily what the user wants. For example, when comparing OD with measurements from ground stations and different EOP it is more realistic to assume that the Earth fixed frames are the same (ground stations didn’t move).
This could probably be implemented by creating a FramesFactory constructor that takes a Frame from another data context and a Predefined selecting a frame in this data context. Since the choice of root frame is arbitrary other frames would then be constructed relative to the selected frame. Would require a significant update to the frame creation code to allow building the tree from either direction, e.g. from GCRF to ITRF or from ITRF to GCRF.
Sharing data between contexts
Sometimes users may only want to reuse part of an existing data context when creating a new one. For example, only update the EOP but use the same leap second file. Under the basic proposal users could do this by setting the same data provider for the leap second file in both data contexts, but multiple copies of the leap second file will then be loaded and stored in memory. A memory optimization could be to create a way for the user to reuse specific data sets from one context to another. Would probably need to reuse instances, e.g. UTCScale, or provide methods to get the underlying data table, e.g. UTCScale.getLeapSeconds(), or cache the data in the providers instead of the factories as suggested in [5].
Use Java’s Service Provider Interface
As suggested in [5] we could add a method for Orekit to detect data loaders using Java’s ServiceLoader capability. This could replace or augment the addEOPHistoryLoader(), addUTCTAIOffsetsLoader(), addProvider(), and addFilter() families of methods. Could simplify configuration for users when reading EOP formats that Orekit does not support natively, e.g. [6].
References
[1] clearFactories() method from test class Utils
[2] https://orekit.org/doc/orekit-day/2019/3%20-%20Quartz%20FDS%20presentation%20for%20Orekit%20Day%20-%20Airbus%20DS.pdf
[3] Thank you for Orekit Day 2019! - #5 by evan.ward
[4] Re: [Orekit Developers] [Orekit Users] design of the DataProviders
[5] RE: [Orekit Developers] [Orekit Users] design of the DataProviders
[6] http://maia.usno.navy.mil/ser7/mark3.out